如何通过这些“超参数”和调整策略优化你的检索增强生成(RAG)流程
针对检索增强生成应用的调整策略
数据科学本质上是一门实验性科学。从“没有免费午餐定理”出发,这个定理阐述了没有万能的算法能够解决所有问题。因此,数据科学家们经常利用实验跟踪系统来调整他们机器学习 (ML) 项目的超参数,以追求最优的性能表现。
本文以数据科学家的视角深入探讨了检索增强生成 (RAG) 流程。文中将讨论一系列可能的“超参数”,通过这些参数的调整,可以有效提升 RAG 流程的表现。类似于深度学习中的实验手段,例如数据增强技术,并不直接是超参数,而是一个可调整和实验的关键因素,本文也会介绍可以应用的不同策略,这些策略本身并不是直接的超参数。
文章围绕以下按其应用阶段分类的“超参数”展开。在 RAG 流程的数据录入阶段,你可以通过以下方法提升性能:
在推理阶段(包括检索和生成),则可以调整:
请注意,本文主要介绍 RAG 在文本应用方面的内容。至于多模态 RAG 应用,可能涉及不同的考量。
数据录入阶段
在构建 RAG 系统时,数据录入阶段是一个关键的准备工序,其过程类似于机器学习中的数据清理和预处理环节。一般来说,数据录入阶段包括以下几个步骤:
- 收集数据
- 数据分割
- 为数据分割生成向量嵌入
- 将向量嵌入及数据分割存入向量数据库
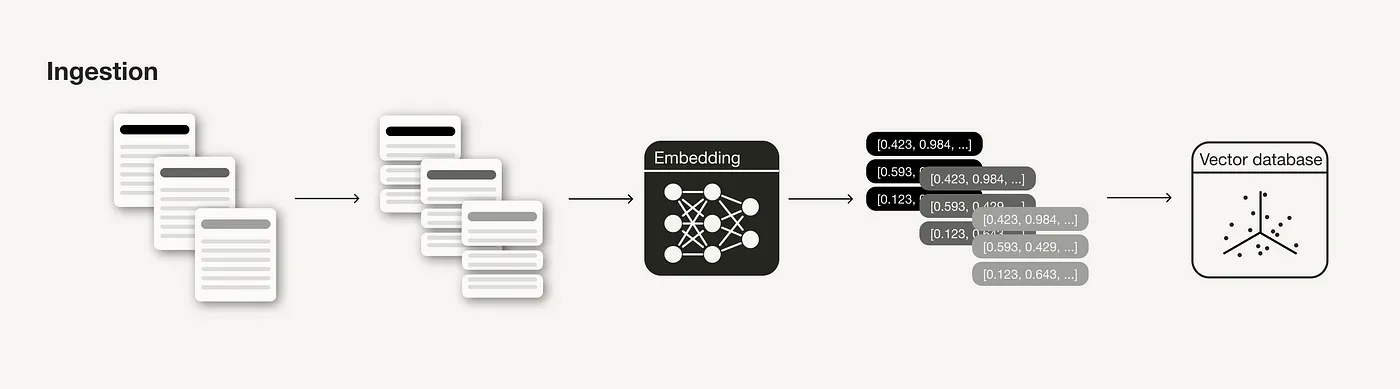
RAG 系统的数据录入阶段
这一部分主要讨论了一些有着显著影响的技术和超参数,通过对它们的应用和调整,可以在后续的推理阶段提高检索到的内容的相关性。
数据清理
和所有数据科学项目一样,数据的质量对 RAG 系统的成果有着直接影响 [8, 9]。在进行后续步骤之前,请确保您的数据满足以下标准:
- 清洁:至少进行基本的数据清理,这在自然语言处理中非常常见,比如确保所有特殊字符都被正确编码。
- 准确:确保您的信息是连贯且事实正确的,以免出现相互矛盾的信息,从而混淆大型语言模型。
文档分块技术
在构建 RAG(检索式生成网络)管道时,将文档进行恰当的分块是关键准备步骤之一,这直接影响系统的性能 [1, 8, 9]。文档分块是一种将长文档拆分成小段或将小段信息组合成连贯段落的技术,旨在生成逻辑上连贯、信息丰富的文档片段。
重要的一点是要选择适当的 分块技术。例如,在 LangChain 中,不同的文本分割器 使用不同的逻辑来切分文档,如基于字符、Token 等。这种选择取决于您手头的数据类型。比如,处理代码类数据和处理 Markdown 文件时,您需要采用不同的分块策略。
理想的 分块长度(chunk_size) 也因应用场景而异:如果是问答系统,可能需要较短的精确信息块;如果是内容摘要,可能需要较长的信息块。同时,块的大小也需恰到好处:太短可能缺乏足够上下文,太长则可能含有过多无关信息。
此外,还需要在不同块之间考虑设置 “滚动窗口”(overlap),以便增加额外的上下文信息。
嵌入模型简介
在你的信息检索系统中,嵌入模型发挥着关键作用。嵌入的品质 极大地影响了检索的效果 [1, 4]。一般来说,嵌入向量的维度越高,其精准度也越高。
想了解更多可替换的嵌入模型?可以参考 Massive Text Embedding Benchmark (MTEB) 排行榜,这里汇集了目前(截至本文写作时)164 种文本嵌入模型的比较。
MTEB 排行榜 – 由 mteb 创建的 Hugging Face Space
尽管通用嵌入模型可以直接使用,但在一些特定场景下,对嵌入模型进行微调 更有利于适应特定的使用环境,避免未来出现领域外问题 [9]。LlamaIndex 的实验显示,微调嵌入模型可以在检索效果上提升大约 5–10% [2]。
需要注意的是,并不是所有嵌入模型都支持微调。例如,OpenAI 提供的 text-ebmedding-ada-002 目前还不支持微调。
元数据
当你在 向量数据库 中存储向量嵌入时,有些数据库支持你将向量与元数据(或非向量化的数据)一同存储。给向量嵌入添加元数据标注 可以在后续的搜索结果处理中发挥重要作用,如进行 元数据筛选 [1, 3, 8, 9]。比如,你可以加入诸如日期、章节或小节的引用等额外信息。
多重索引技术
在元数据无法充分区分不同上下文类型的情况下,您可以考虑尝试多重索引技术 [1, 9]。比如,针对不同文档类型采用不同的索引策略。但请注意,这样做需要在数据检索时加入索引路由机制 [1, 9]。如果您对如何利用元数据和分离集合有更深的兴趣,建议您深入了解原生多租户这一概念。
索引算法
为了实现在大数据量下快速且高效的相似性搜索,向量数据库和索引库通常采用近似最近邻 (ANN) 搜索方法,而不是传统的 k-最近邻 (kNN) 搜索。ANN 算法通过近似计算来定位最近邻,因此可能在精确度上稍逊于 kNN 算法。
您可以考虑尝试多种ANN 算法,例如 Facebook Faiss 的聚类算法、Spotify Annoy 的树状结构算法、Google ScaNN 的向量压缩技术,以及 HNSWLIB 的邻近图算法。这些算法中许多都提供了可调整的参数,如 HNSW 的 ef、efConstruction 和 maxConnections [1]。
另外,您还可以为这些索引算法启用向量压缩技术。虽然向量压缩可能会牺牲一定的精度,但通过合理选择压缩算法并调整参数,您可以在保证效率的同时最大限度地减小精度损失。
不过,在实际应用中,这些参数通常由专门的研究团队在进行基准测试时调整,而非由 RAG 系统的开发人员设置。如果您想通过调整这些参数来提高系统性能,我推荐您阅读这篇文章作为入门:
关于 RAG 评估的概述 | Weaviate – 向量数据库
推理阶段(检索与生成)
RAG 管道的核心是检索和生成两大部分。这一节主要介绍提升检索效果的策略(如查询转换、检索参数、高级检索策略 以及 重排序模型),因为相比之下,检索部分对整体影响更大。同时,也会简要介绍一些提升生成部分效果的方法(比如使用大语言模型 (LLM) 和 提示工程 (prompt engineering))。
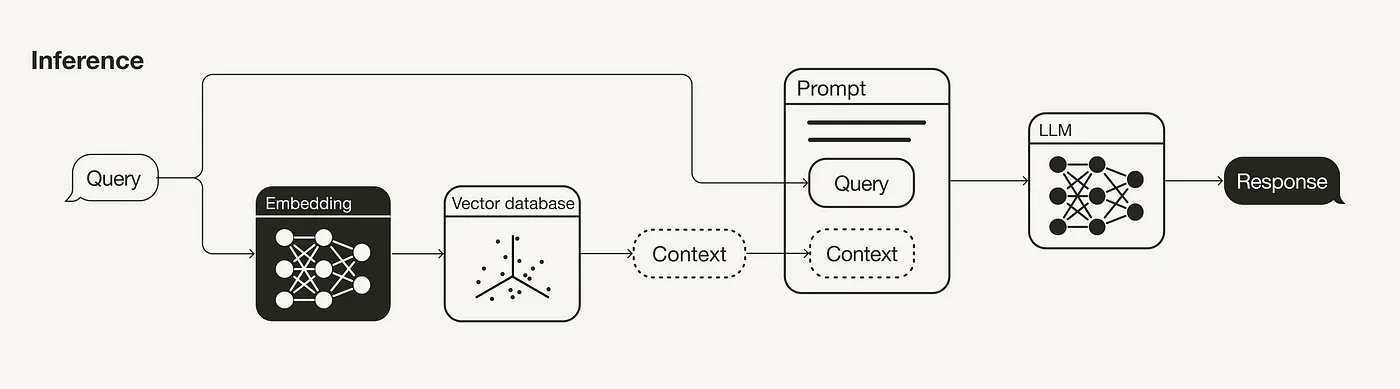
查询转换
在 RAG 管道中,用于检索附加信息的搜索查询也会被嵌入到向量空间里,因此查询的措辞会直接影响搜索结果。所以,如果你发现搜索结果不尽人意,可以尝试以下几种查询转换方法 [5, 8, 9],以提升检索效率:
- 重新措辞: 利用大语言模型 (LLM) 改写你的查询语句,然后再试一次。
- 假设性文档嵌入(HyDE): 使用大语言模型 (LLM) 生成一个针对查询的假设性回答,并结合使用以进行检索。
- 子查询: 将复杂的长查询分解成几个简短的小查询。
检索参数
检索过程是 RAG(检索增强生成)流程的核心环节。首先,你需要决定仅使用语义搜索是否足够,或者你是否想尝试更复杂的混合搜索。
在选择混合搜索时,你需要研究如何在稀疏和密集检索方法之间进行有效的权重分配 [1, 4, 9]。这就涉及到调整 **alpha** 参数,该参数负责平衡基于语义的搜索(**alpha = 1**)和基于关键词的搜索(**alpha = 0**)的重要性。
另一个关键因素是检索结果的数量。检索到的上下文数量会影响所用上下文窗口的长度(参见 提示工程)。此外,如果你使用的是重排模型,你还需要考虑向模型输入多少个上下文(参见 重排序模型)。
请注意,虽然你可以更改用于语义搜索的相似度度量参数,但最好不要随意变动,而是根据所使用的嵌入模型来设定。例如,[text-embedding-ada-002](https://platform.openai.com/docs/guides/embeddings/what-are-embeddings) 支持余弦相似度,而 [multi-qa-MiniLM-l6-cos-v1](https://huggingface.co/sentence-transformers/multi-qa-MiniLM-L6-cos-v1#technical-details) 支持余弦相似度、点积和欧几里得距离。
高级检索策略
本节内容足够编写成一篇独立文章。为了保持简洁,我们仅提供一个概览。想要深入了解下面提到的技术,我建议你参考 DeepLearning.AI 提供的这个课程:
这一节的核心理念是:用于检索的数据块不必是用于生成内容的同一数据块。理想情况下,应该嵌入更小的数据块来进行检索(参见 文档分块),但同时检索更广泛的上下文。 [7]
- 句子窗口检索: 在检索时,不只是找到相关的单个句子,而是要获取该句子前后的相关句子。
- 自动合并检索: 文档按树状结构组织。在查询时,可以把若干个小的、相关的数据块合并成一个更大的上下文。
重排序模型
虽然语义搜索是根据搜索查询与上下文的语义相似度来进行的,但“最相似”并不总等同于“最相关”。像 Cohere 的 Rerank 这样的重排序模型能够通过为每个检索结果计算与查询相关性的得分,帮助排除不相关的搜索结果 [1, 9]。
“最相似”不总意味着“最相关”
使用重排序模型时,你可能需要重新调整搜索结果的数量,以及你想要输入到大语言模型 (Large Language Model) 的经过重排序的结果数量。
和 嵌入模型 一样,你可能需要尝试针对你的特定应用场景对重排序模型进行微调。
大语言模型 (LLM)
在生成回应的过程中,大语言模型 (LLM) 扮演着核心角色。正如嵌入模型那样,LLM 的选择取决于您的具体需求,比如选择开放源代码还是专有模型、考虑推理成本、上下文长度等因素。您可以从众多 LLM 中挑选最适合您的 [1]。
与处理嵌入模型或重新排序模型时相似,您可能需要针对特定场景对 LLM 进行微调,以便更好地融入特定的词汇或语调。
提示工程 (Prompt engineering)
如何巧妙地设计您的提示词或问题,将直接影响到 LLM 的回答效果 [1, 8, 9]。一个好的提示词设计能让 LLM 提供更加准确和高质量的回答。
请确保您的回答仅基于搜索结果,不要添加任何其他信息!
这一点非常关键!您的回答必须严格基于提供的搜索结果。
并请说明您的回答为何与搜索结果密切相关!
在提示词中加入少样本 (few-shot) 示例,可以有效提升 LLM 生成内容的质量。
正如在检索参数一节中提到的,探索在提示词中加入的上下文数量也是值得尝试的。虽然增加相关上下文有助于提高您的 RAG (检索增强生成) 系统的性能,但同时也可能产生“迷失在中间”[6]的现象,即 LLM 无法有效识别被放置在众多上下文中间的相关信息。
检索增强生成 (Retrieval-Augmented Generation, RAG): 从理论到 LangChain 的实际应用
总结
随着越来越多的开发人员积极探索 RAG (检索增强生成) 管道的原型设计,如何将 RAG 管道提升至适用于生产环境的性能水平变得愈发重要。本文探讨了在 RAG 管道不同阶段可以调整的各种“超参数”和其他可调节项:
文章在数据录入阶段中介绍了以下策略:
- 数据清洗:确保数据的清洁和准确性。
- 分块:选择合适的分块技术、块大小(
chunk_size)和块之间的重叠(overlap)。 - 嵌入模型:选择嵌入模型,包括模型的维度以及是否需要进行微调。
- 元数据:决定是否使用元数据以及选择哪些元数据。
- 多重索引:决定是否为不同的数据集合使用多个索引。
- 索引算法:选择和调整近似最近邻 (ANN) 和向量压缩算法,虽然这通常不是实践者所调整的。
以及在推理阶段(检索和生成)中介绍的策略: